キャッシュサーバーとおしゃべり
DNSクライアントを実装し、キャッシュサーバーに再帰的問い合わせをしてみたいと思います。DNSの仕様は現在では色々と継ぎ足されてより複雑になっていますので、RFC1034と1035の域を出ない範囲のレガシーなクライアントを実装します。また今回はTCPフォールバックは対応しません。
開発環境は以下の通りです:
- Windows 10 x64
- Visual Studio 2019 Community
- C++17
下ごしらえ
Winsock2を使うので必要なファイルのインクルードやリンクするファイルの指定を行います。
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
#include <ws2tcpip.h>
#include <Windows.h>
#include <tchar.h>また、main()関数などでWinsock2を使うための初期化処理/終了処理を書く必要があります。
int _tmain(int argc, TCHAR** argv)
{
// Winsockの初期化処理
WSADATA wsa;
if (WSAStartup(MAKEWORD(2, 2), &wsa) != 0)
return -1;
// 問い合わせる
auto cacheserver = "8.8.8.8";
auto port = "53";
auto fqdn = "www.microsoft.com"s;
u_short id = 0x1234;
u_short type = TYPE_A;
Response response;
bool ret = query(cacheserver, port, fqdn, type, id, response);
if (!ret) {
// エラー: response.headerをチェック
}
else {
// typeに応じてresponse.answer,response.authority,response.additionをチェック
}
// Winsockの終了処理
if (WSACleanup() != 0)
return -1;
return 0;
}
初期化処理と終了処理の間をこれから実装して行きます。
問い合わせメッセージ
DNSメッセージは、基本的にUDPの53番ポートで通信が行われ、メッセージ長は512バイトまでとなっており、ヘッダー部+問い合わせ部+0個以上のリソースレコードで構成されます。
問い合わせ/応答ともに共通の構造が使われます。
ヘッダー部
#pragma pack(push, 1)
struct Header final
{
u_short id; // メッセージを識別する任意の16ビットの数値
u_short flags; // 各種フラグ
u_short qdcount; // 問い合わせの数
u_short ancount; // 回答レコードの数
u_short nscount; // 権威レコードの数
u_short arcount; // 付加情報レコードの数
};
#pragma pack(pop)各16ビットのフィールドはビッグエンディアンなので、送信前に全てビッグエンディアンに変換し、受信後にリトルエンディアンに戻します。各フィールド間に隙間(パディング)が入っては困るので1バイトアライメントでパッキングする様指定しています。
id フィールド
メッセージを識別する16ビットの数値です。DNSサーバーはリクエストで送られてきたidの値をそのまま返します。クライアントはどのリクエストのレスポンスなのかをこのidで識別します。
flags フィールド
この16ビットのフィールドは複数のフラグで構成されています。

| フィールド名 | サイズ (ビット) | 説明 |
|---|---|---|
| QR | 1 | 0: 問い合わせ 1: 応答 |
| Opcode | 4 | 0: 標準問い合わせ(正引き) 1: 逆問い合わせ(逆引き) 2: サーバーステータスのリクエスト 3~15: 予約済み |
| AA | 1 | 応答のみ。このビットが1の時、問い合わされたドメイン名の権威である事を示す。 |
| TC | 1 | 応答のみ。このビットが1の時、応答が512バイトに収まらなかったことを示す。 |
| RD | 1 | 0: 反復問い合わせ 1: 再帰的問い合わせ |
| RA | 1 | 応答のみ。このビットが1の時、サーバーは再帰問い合わせが利用可能かを示す。 |
| Z | 3 | 予約済み。0でなければならない。 |
| RCODE | 4 | 応答コード。 0: エラーなし 1: メッセージの書式エラー 2: サーバー側の問題で問い合わせを処理できなかった 3: 問い合わされたドメイン名が存在しない 4: リクエストされた種類の問い合わせをサポートしていない 5: 問い合わせの拒否 |
qdcount フィールド
問い合わせではドメイン名の数を指定する。応答では問い合わされたドメイン名の数を示す。通常は1です。
ancount フィールド
応答のみ。回答部のリソースレコード数を示す。問い合わせでは0を指定します。
nscount フィールド
応答のみ。権威あるネームサーバーのリソースレコード数を示す。 問い合わせでは0を指定します。
arcount フィールド
応答のみ。付加情報のリソースレコード数を示す。 問い合わせでは0を指定します。
// ヘッダーをストリームに出力する
void writeHeader(std::ostream& ostr, Header& header)
{
header.toBigEndian();
ostr.write(reinterpret_cast<const char*>(&header), sizeof(Header));
header.toLittleEndian();
}問い合わせ部
ヘッダーに続いて問い合わせ部が続きます。問い合わせ部はQNAME、QTYPE、QCLASSで構成されます。
QNAME
QNAMEは問い合わせるドメイン名の文字列を簡単にエンコードしたものになります。エンコード方法はドメイン名をドットで各ラベルに区切り、各ラベルの先頭にそのラベル長を示す1オクテットを付与したものを結合し、最後に終端を示す1オクテットの0を加えます。ただし、ラベル長を示す1オクテットの上位2ビットは予約されているため、ラベル長が63オクテットを超えてはいけません。また、QNAME全体で255オクテットを超えてはいけません。また、2オクテット境界にするためのパディングは不要です(あってはなりません)。
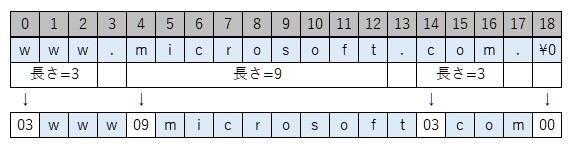
メッセージ内で取り扱うドメイン名(*NAME)は全て同様にエンコードされた形で現れます。
// FQDNをエンコードしてストリームに出力する
void writeFqdn(std::ostream& ostr, const std::string& str)
{
if (str.length() + 1 > Limits::MAX_NAME)
throw InvalidFormat();
size_t end = str.length();
size_t beg = 0, cur = 0;
do {
// ドットを検索
cur = str.find('.', beg);
if (cur == std::string::npos) {
cur = end; // ドットがもうないので省略されたものとみなす
}
// ラベル長とラベルの出力
auto val = cur - beg;
if (val > Limits::MAX_LABEL) {
throw InvalidFormat();
}
ostr << static_cast<u_char>(val);
for (auto i = beg; i < cur; ++i) {
ostr << str[i];
}
// 終端文字の出力
if (cur == end) {
ostr << static_cast<u_char>(0);
return;
}
beg = cur + 1;
} while (beg < end);
throw InvalidFormat();
}QTYPE
QTYPEは問い合わせるリソースレコードの種類を表す2オクテットの数値です。
| タイプ名 | 対応値 | 意味 |
|---|---|---|
| A | 1 | IPv4アドレス |
| NS | 2 | 権威ネームサーバーのドメイン名 |
| CNAME | 5 | 別名の正規名 |
| SOA | 6 | ゾーンの権威の開始を示す |
| MX | 15 | メールサーバーのドメイン名 |
| AAAA | 28 | IPv6アドレス |
QCLASS
QCLASSは問い合わせる名前のネットワーククラスを表す2オクテットの数値です。ここではインターネット(IN)しか扱わないので常に1です。インターネット以外にもカオス(CH、3)やヘシオド(HS、4)、あらゆるクラスを示す255も指定出来るそうですが、ここでは無視します。
// u_short値をストリームに出力する
void writeUShort(std::ostream& ostr, u_short val)
{
val = ::htons(val);
ostr.write(reinterpret_cast<const char*>(&val), sizeof(u_short));
}問い合わせメッセージのまとめ
上記を踏まえ、キャッシュサーバーにwww.microsoft.com.のAレコードを再帰的問い合わせするDNSメッセージは以下の様になります。
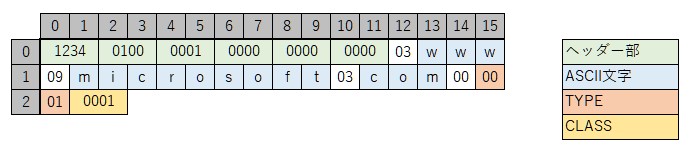
最初の緑色で示された12オクテットがヘッダー部です。今回はメッセージの識別子を0x1234にしました。flagsは再帰的問い合わせを示すRDビットだけが立っていて(0x0100)、問い合わせ(qdcount)が1件であることを示しています。QNAMEは19オクテットですが偶数パディングされず、すぐにQTYPE、QCLASSが続いて、35オクテットのメッセージになっています。
// 問い合わせメッセージを作成する
std::string buildMessage(const std::string& fqdn, u_short type, u_short id)
{
// ヘッダーの初期化
Header header{ 0 };
header.id = id;
header.flags = RD; // 再帰的問い合わせ(決め打ち)
header.qdcount = 1;
// メッセージの作成
std::ostringstream request;
writeHeader(request, header);
writeFqdn(request, fqdn);
writeUShort(request, type);
writeUShort(request, CLASS_IN);
return request.str();
}メッセージの送受信
問い合わせメッセージが用意できましたので、キャッシュサーバーにメッセージを送って行きたいと思います。今回利用するキャッシュサーバーはGoogle Public DNSの8.8.8.8:53(udp)です。
std::string sendMessage(const char* cacheserver, const char* port, const std::string& request)
{
// ソケットの作成
addrinfo* addr, hints;
memset(&hints, 0, sizeof(addrinfo));
hints.ai_family = AF_UNSPEC;
hints.ai_socktype = SOCK_DGRAM;
hints.ai_protocol = IPPROTO_UDP;
hints.ai_flags = AI_NUMERICHOST | AI_NUMERICSERV;
if (getaddrinfo(cacheserver, port, &hints, &addr) != 0) {
throw SocketError();
}
auto sock = socket(addr->ai_family, addr->ai_socktype, addr->ai_protocol);
if (sock == INVALID_SOCKET) {
auto err = WSAGetLastError();
freeaddrinfo(addr);
throw SocketError(err);
}
// リクエストの送信
auto sendlen = sendto(sock, request.c_str(), (int)request.length(), 0, addr->ai_addr, addr->ai_addrlen);
if (sendlen == SOCKET_ERROR) {
auto err = WSAGetLastError();
freeaddrinfo(addr);
closesocket(sock);
throw SocketError(err);
}
// レスポンスの受信
std::string response(Limits::MAX_UDPDATA, 0);
auto addrlen = addr->ai_addrlen;
auto recvlen = recvfrom(sock, response.data(), response.size(), 0, addr->ai_addr, reinterpret_cast<int*>(&addrlen));
if (recvlen == SOCKET_ERROR) {
auto err = WSAGetLastError();
freeaddrinfo(addr);
closesocket(sock);
throw SocketError(err);
}
response.resize(recvlen);
freeaddrinfo(addr);
closesocket(sock);
return response;
}この実装の場合、1回の送受信の度にソケットを作り直していてローカルポートが都度割り当て直されるため、マルチスレッドでこの関数を呼び出してもrecvfrom()は直前のsendto()で送った問い合わせの応答を読みだせます。
しかし、もしソケットを1つ作っておいてそれを使い回す実装にした場合は、recvfrom()で受信したメッセージがどのsendto()で送信したメッセージへの応答か分からないので、後でHeader::idを使ってどの問い合わせの応答を受信したかを判断する必要があります。
bool query(const char* cacheserver, const char* port, const std::string& fqdn, u_short type, u_short id, Response& response)
{
auto rawrequest = buildMessage(fqdn, type, id);
auto rawresponse = sendMessage(cacheserver, port, rawrequest);
if (rawresponse.size() == 0)
return false;
return parseMessage(id, rawresponse, response);
}問い合わせメッセージの作成、キャッシュサーバーとの送受信が済みましたので、応答メッセージの解析に進みます。
応答メッセージ
応答メッセージを読み解く
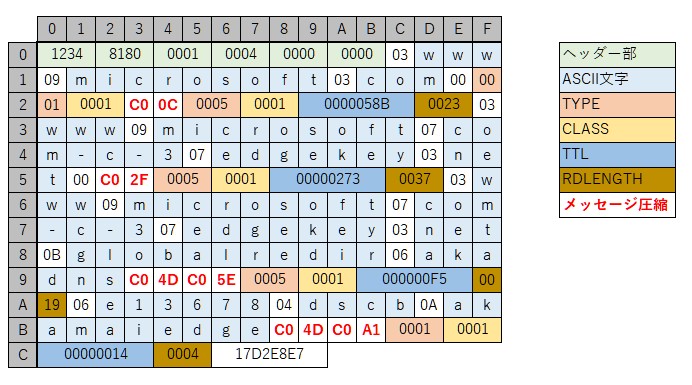
前述のwww.microsoft.comのAレコードについて再帰的問い合わせをする35オクテットの問い合わせメッセージをキャッシュサーバーに送信すると、下図の様な202オクテットの応答メッセージを受け取りました。この応答メッセージを参照しながら読み解いて行きたいと思います。
struct Response
{
Header header;
std::string qname;
u_short qtype;
u_short qclass;
std::vector<ResourceRecord> answer;
std::vector<ResourceRecord> authority;
std::vector<ResourceRecord> addition;
};応答メッセージの解析結果を格納するResponse構造体を定義しておきます。ResourceRecord構造体の定義は後述します。
オフセットアドレス
次の項目の「メッセージ圧縮」以降で「オフセットアドレス」という表現が出てきますが、これは「ヘッダーの先頭からのオフセットアドレス」を差します。上図の左上の0x00がヘッダーの先頭になります。
メッセージ圧縮
応答メッセージ内のドメイン名は、上位ドメインが重複していたりと、同じバイト列が並ぶことが多いため、参照を用いてメッセージ長を小さくする仕組みがあります。
ドメイン名が現れる場所では、通常63(0x3F)以下の1オクテットのラベル長で始まりますが、ラベル長の上位2ビットが立っている(0xC0)場合は、そこから先は、その下位6ビットと次の1オクテットを合わせてオフセットアドレスとして、そこをドメイン名として参照します。
図4.ではオフセット0x23の値が0xC0で上位2ビットが立っているので、次の1オクテット(0x0C)と合わせて上位2ビットをクリアした(0xC0‘0C & 0x3FFF)==0x0Cをオフセットアドレスとしてドメイン名の参照を行います。この場合、0x0CはQNAMEの始まりを差していて、QNAMEは19オクテットありますので0xC00Cの2オクテットと比べて17オクテット削減出来ていることになります。
このメッセージ圧縮は、ドメイン名全体かドメイン名の末尾でのみ行われます。また、参照先でさらに圧縮されていることがあります。
ヘッダー部
応答メッセージを解析するためにparseMessage()を実装して行きます。
bool parseMessage(u_short id, const std::string& rawresponse, Response& response)
{
auto pTop = rawresponse.c_str(); // 応答メッセージの先頭を表す
auto pEnd = pTop + rawresponse.size(); // 応答メッセージの終端を表す
auto pCur = pTop; // 次に解析すべき位置を示す
// ヘッダーの解析
response.header = *reinterpret_cast<const Header*>(pCur); // ヘッダー部をコピー
pCur += sizeof(Header); // ヘッダー分のポインタを進める
response.header.toLittleEndian(); // ヘッダーをリトルエンディアンにする
if (response.header.id != id)
return false; // メッセージ識別子が一致していない
if (!response.header.isSet(QR) || !response.header.isSet(RD) || !response.header.isSet(RA))
throw InvalidFormat(); // 応答でない || 再帰的問い合わせでない || 再帰的問い合わせに対応していない
if (response.header.getRCode() != 0)
return false; // 問い合わせが正常に処理されなかった図4.より、まず応答メッセージの先頭にはHeader構造体がありますので、Response構造体のheaderフィールドにコピーし、リトルエンディアンに変換してから内容を確認します。
idフィールドに問い合わせと同じ数値が入っています。これでどの問い合わせに対する応答か判別できます。
flagsフィールドは、まず再帰問い合わせを示すRDビット(0x0100)が立っています。応答メッセージであることを示すQRビット(0x8000)と、サーバーが再帰問い合わせに対応していることを示すRAビット(0x0080)が立っています。そして、応答コードを示すRCODE(下位4ビット)が0なので、エラーなしであることが示されています。ここでTCビットが立っている場合、TCPで接続し直します。TCP接続によるメッセージの送受信はヘッダーの前に2オクテットのメッセージ長が必要です。
qdcountフィールドは、問い合わせ部が1件ある事を示していて、ヘッダー部の直後にそれがある事が図からも分かります(オフセットアドレスで0x0Cから0x22まで)。
ancountフィールドは、回答部にリソースレコードが4件ある事を示しています。
nscountとarcountフィールドは、権威部と付加情報部にリソースレコードが無いことを示しています。
問い合わせ部
続く問い合わせ部には、問い合わせ内容を示すQNAMEとQTYPEとQCLASSがあります。それぞれを解析し、Response構造体の対応するフィールドに代入して行きます。
// 問い合わせ部の解析
// QNAME
pCur = parseName(pTop, pEnd, pCur, response.qname);
// QTYPE
pCur = parseUShort(pTop, pEnd, pCur, response.qtype);
// QCLASS
pCur = parseUShort(pTop, pEnd, pCur, response.qclass);まずドメイン名を解析しストリームに返すparseName()を実装します。また、文字列として返すラッパーも用意して、そちらを呼び出しています。ここでドメイン名のメッセージ圧縮は展開されますが、ドット区切りの文字列には変換しません。
// ドメイン名の読み込み(メッセージ圧縮を解除するけど、デコードは行わない)
const char* parseName(const char* pTop, const char* pEnd, const char* pCur, std::ostream& name)
{
while (pCur < pEnd) {
u_char ch = static_cast<u_char>(*pCur++);
if (ch == 0) { // ラベル長が0 => ドメイン名の終端
name << ch;
return pCur;
}
else if ((ch & 0xC0) == 0) { // ラベル長(0x3F以内)
name << ch;
for (u_char i = 0; i < ch; ++i) // ラベル長分読み込む
if (pCur < pEnd)
name << *pCur++;
else
throw InvalidFormat(); // ここで終端に達するのはエラー
}
else if ((ch & 0xC0) == 0xC0) { // 上位2ビットが11の場合はメッセージ圧縮されている
auto ch2 = static_cast<u_char>(*pCur++); // 次の1オクテットも読み込む
u_short offset = ((ch & 0x3F) << 8) + ch2; // chの下位6ビットとch2がpTopからのオフセットを差している
auto unused = parseName(pTop, pEnd, pTop + offset, name); // pTop+offsetで示される位置のドメイン名を読み込む
return pCur; // 参照先ではなく元のpCurを返す
}
else {
throw NotImplemented();
}
}
throw InvalidFormat(); // ここに来たらエラー
}
// ドメイン名の読み込み(std::stringで受け取るラッパー関数)
const char* parseName(const char* pTop, const char* pEnd, const char* pCur, std::string& name)
{
std::ostringstream ostr;
auto ret = parseName(pTop, pEnd, pCur, ostr);
name = ostr.str();
return ret;
}TYPEやCLASSは2オクテットで表されるので、2オクテットを読み込むparseUShort()と後で使う4オクテットを読み込むparseUInt()を実装します。
// 2オクテット値の読み込み&リトルエンディアンに変換
const char* parseUShort(const char* pTop, const char* pEnd, const char* pCur, u_short& value)
{
if (pCur + 1 >= pEnd)
throw InvalidFormat(); // ここで終端に達するのはエラー
value = static_cast<u_char>(*pCur++);
value = (value << 8) + static_cast<u_char>(*pCur++);
return pCur;
}
// 4オクテット値の読み込み&リトルエンディアンに変換
const char* parseUInt(const char* pTop, const char* pEnd, const char* pCur, u_int& value)
{
if (pCur + 3 >= pEnd)
throw InvalidFormat(); // ここで終端に達するのはエラー
value = static_cast<u_char>(*pCur++);
value = (value << 8) + static_cast<u_char>(*pCur++);
value = (value << 8) + static_cast<u_char>(*pCur++);
value = (value << 8) + static_cast<u_char>(*pCur++);
return pCur;
}リソースレコード
応答メッセージには、問い合わせ内容に応じて回答部、権威部、付加情報部にリソースレコードがあります。それぞれ応答メッセージのヘッダー部のancount、nscount、arcountでそれぞれのリソースレコード数が示されています。
| フィールド名 | サイズ (オクテット) | 意味 |
|---|---|---|
| NAME | n | リソースレコードに関連するドメイン名を示す。 |
| TYPE | 2 | リソースレコードのタイプ。RDATAで示されるデータの意味を示す。 |
| CLASS | 2 | リソースレコードのクラス。RDATAで示されるデータのクラスを示す。 |
| TTL | 4 | このリソースレコードの有効期間を秒単位で示す。 |
| RDLENGTH | 2 | RDATAのオクテット数を示す。 |
| RDATA | n | リソースデータを示す。フォーマットはTYPEに依存する。 |
struct ResourceRecord
{
std::string name;
u_short type;
u_short cls;
u_int ttl;
std::string resource;
};ここでもう一度digの応答を見て、上記のフォーマットと対比してみましょう。回答部(ANSWER SECTION)の赤太字の部分を見て下さい。
> dig "@8.8.8.8" www.microsoft.com
; <<>> DiG 9.16.1-Ubuntu <<>> @8.8.8.8 www.microsoft.com
; (1 server found)
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 7725
;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;www.microsoft.com. IN A
;; ANSWER SECTION:
www.microsoft.com. 1616 IN CNAME www.microsoft.com-c-3.edgekey.net.
www.microsoft.com-c-3.edgekey.net. 780 IN CNAME www.microsoft.com-c-3.edgekey.net.globalredir.akadns.net.
www.microsoft.com-c-3.edgekey.net.globalredir.akadns.net. 690 IN CNAME e13678.dscb.akamaiedge.net.
e13678.dscb.akamaiedge.net. 20 IN A 23.210.232.231
;; Query time: 30 msec
;; SERVER: 8.8.8.8#53(8.8.8.8)
;; WHEN: Thu Oct 07 14:27:40 JST 2021
;; MSG SIZE rcvd: 213| www.microsoft.com. | NAME |
| 1616 | TTL |
| IN | CLASS |
| CNAME | TYPE |
| www.microsoft.com-c-3.edgekey.net. | RDATARDLENGTHRDLENGTH |
digではTTLの位置がCLASSの前になってはいますが、概ねリソースレコードをそのまま出力しているのが分かります。これでリソースレコードがどういった物なのか理解し易くなったと思います。
主なTYPEごとのRDATAのフォーマット
TYPE=A
TYPEがA(1)の時、RDLENGTH=4でRDATAはIPv4アドレスを示します。”192.168.100.20″の様な文字列形式ではなく、0xC0A86414の様にビッグエンディアンのバイナリ形式になります。
TYPE=NS
TYPEがNS(2)の時、NAMEで示されるドメイン名について権威があるネームサーバーのドメイン名が示されます。QNAMEと同じ様にエンコードとメッセージ圧縮されています。RDLENGTHはメッセージ圧縮後のサイズを示します。
TYPE=CNAME
TYPEがCNAME(5)の時、RDATAはNAMEで示される別名の正規名を示すドメイン名となります。このドメイン名もTYPE=NSの時と同様にメッセージ圧縮されています。
TYPE=MX
TYPEがMX(15)の時、RDATAはNAMEで示されるメールアドレスのドメイン名に対応するメールサーバーのドメイン名とその優先度を示します。書式は2オクテットの優先度にドメイン名が続きます。 このドメイン名もTYPE=CNAMEの時と同様にメッセージ圧縮されています。
// リソースレコードの解析
const char* parseResourceRecord(const char* pTop, const char* pEnd, const char* pCur, ResourceRecord& rr)
{
// NAME
pCur = parseName(pTop, pEnd, pCur, rr.name);
// TYPE
pCur = parseUShort(pTop, pEnd, pCur, rr.type);
// CLASS
pCur = parseUShort(pTop, pEnd, pCur, rr.cls);
// TTL
pCur = parseUInt(pTop, pEnd, pCur, rr.ttl);
// RDLENGTH
u_short rdlen;
pCur = parseUShort(pTop, pEnd, pCur, rdlen);
auto const pRData = pCur;
// RDATA
if ((rr.type == TYPE_A && rdlen == 4) || (rr.type == TYPE_AAAA && rdlen == 16)) {
// AレコードはIPv4アドレス、AAAAレコードはIPv6アドレスをリソースとして持つ
// IPアドレスはバイト列として読み込むだけで、文字列表記に直さない
std::ostringstream ostr;
for (u_short i = 0; i < rdlen; ++i) {
ostr << *pCur++;
}
rr.resource = ostr.str();
}
else if (rr.type == TYPE_CNAME || rr.type == TYPE_NS) {
// CNAME、NSレコードはドメイン名をリソースとして持つ
pCur = parseName(pTop, pEnd, pCur, rr.resource);
}
else if (rr.type == TYPE_MX) {
// MXレコードは2オクテットの優先順位とドメイン名をリソースとして持つ
std::ostringstream mxstr;
u_short temp;
pCur = parseUShort(pTop, pEnd, pCur, temp);
mxstr.write(reinterpret_cast<const char*>(&temp), sizeof(u_short));
pCur = parseName(pTop, pEnd, pCur, mxstr); // 圧縮メッセージの展開はしておく
rr.resource = mxstr.str();
}
else if (rr.type == TYPE_SOA) {
// SOAレコードは MNAME,RNAME,SERIAL,REFRESH,RETRY,EXPIRE,MINIMUM
std::ostringstream soastr;
u_int temp;
pCur = parseName(pTop, pEnd, pCur, soastr); // 圧縮メッセージの展開はしておく
pCur = parseName(pTop, pEnd, pCur, soastr); // 圧縮メッセージの展開はしておく
pCur = parseUInt(pTop, pEnd, pCur, temp);
soastr.write(reinterpret_cast<const char*>(&temp), sizeof(u_int));
pCur = parseUInt(pTop, pEnd, pCur, temp);
soastr.write(reinterpret_cast<const char*>(&temp), sizeof(u_int));
pCur = parseUInt(pTop, pEnd, pCur, temp);
soastr.write(reinterpret_cast<const char*>(&temp), sizeof(u_int));
pCur = parseUInt(pTop, pEnd, pCur, temp);
soastr.write(reinterpret_cast<const char*>(&temp), sizeof(u_int));
pCur = parseUInt(pTop, pEnd, pCur, temp);
soastr.write(reinterpret_cast<const char*>(&temp), sizeof(u_int));
rr.resource = soastr.str();
}
else {
// 未対応のものはRDLENGTH分だけRDATAを受け取り解析はしない
std::ostringstream ostr;
for (u_short i = 0; i < rdlen; ++i) {
ostr << *pCur++;
}
rr.resource = ostr.str();
}
// リソース部を解析した結果、RDLENGTHと不整合があればエラー
if (pCur - pRData != rdlen)
throw InvalidFormat();
return pCur;
}回答部、権威部、付加情報部のリソースレコード
図4ではリソースレコードは、オフセットアドレスで言うと0x23~0x51、0x52~0x94、0x95~0xB9、0xBA~0xC9の4か所に分けられますが、可変長レコードなため、頭から1バイトずつ解析して行かないといけません。各種レコード数はヘッダーで示されていますので、それを元に処理していきます。
// 回答部
for (u_short answer = 0; answer < response.header.ancount; ++answer) {
ResourceRecord rr;
pCur = parseResourceRecord(pTop, pEnd, pCur, rr);
response.answer.push_back(rr);
}
// 権威部
for (u_short authority = 0; authority < response.header.nscount; ++authority) {
ResourceRecord rr;
pCur = parseResourceRecord(pTop, pEnd, pCur, rr);
response.authority.push_back(rr);
}
// 付加情報部
for (u_short addition = 0; addition < response.header.arcount; ++addition) {
ResourceRecord rr;
pCur = parseResourceRecord(pTop, pEnd, pCur, rr);
response.addition.push_back(rr);
}
// 正しく終端まで来てなければエラー
if (pCur != pEnd)
throw InvalidFormat();
return true;
}これで応答メッセージの解析が完了し、解析結果がResponse構造体に格納されました。
プログラマーとDNS(1)
プログラマーとDNS(2)
プログラマーとDNS(3)
